关于python中对url点段处理的若干问题
0x00 Python requests的处理
这个问题是在我写一个poc时发现的,具体见Zoho CVE-2021-40539/)
简单来说就是像下面的代码
1 | import requests |
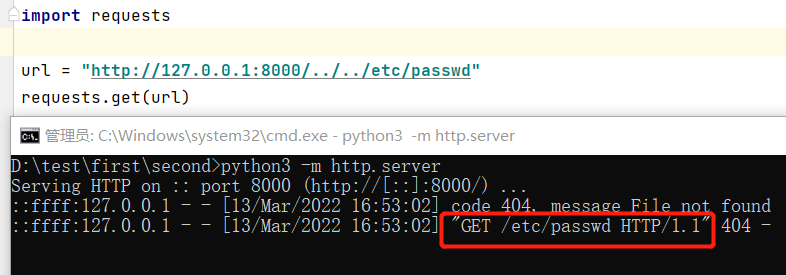
上图可以发现服务器收到的请求路径为
/etc/passwd而不是我们设置的url =../../etc/passwd
我们想要让他去请求http://127.0.0.1/../../path的路径,但实际上他会变成请求http://127.0.0.1/path,点段被吃掉了!
这是因为urllib3根据RFC3986规范做的更改
具体内容如下图

可以看到标题意思即为“去除点段”,大致意思就是将url路径中以.或..作为一个完整路径段时,要将其去除
这个规范本意上是为了规范url的写法,但是对于安全行业来说,这不是个好的规范,因为通常我们需要发送像http://ip/../../path之类的请求来尝试目录穿越或者其他漏洞触发点
0x01 解决方案
参考:https://mazinahmed.net/blog/testing-for-path-traversal-with-python/
这是一个国外研究员的博客,他也是在urllib3仓库提出关于urllib3删除点段的issue的研究员,博客里他总结了几点用于解决urllib3删除点段的方案
方案1 urllib.request
1 | url = "https://example.com/../../../etc/passwd" |
效果:
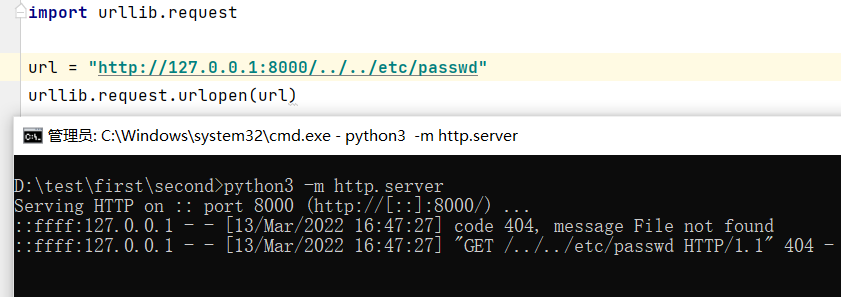
可以看到服务器端确实收到了../../etc/passwd的请求
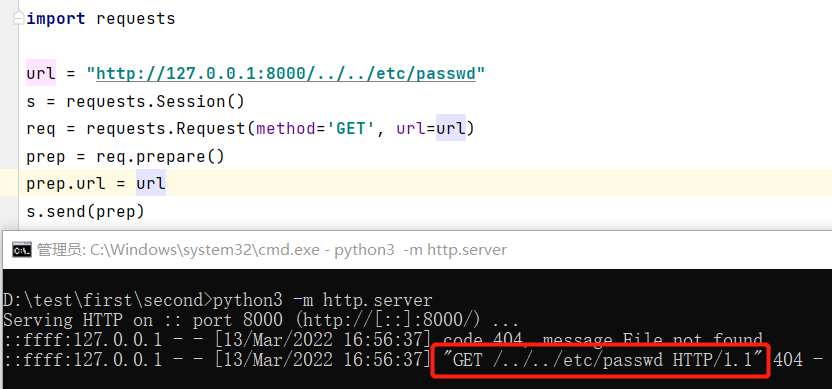
方案2 requests.Request
1 | url = "https://example.com/../../../etc/passwd" |
这么写并不是没有根据的,我们可以跟踪一下requests.get(url),会发现他先跳到自身的request方法
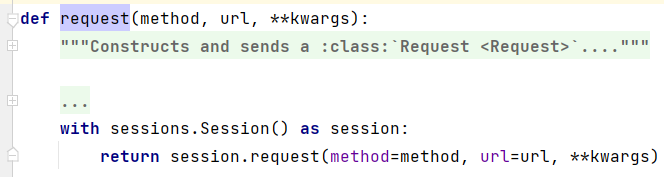
这里使用Session()的request方法
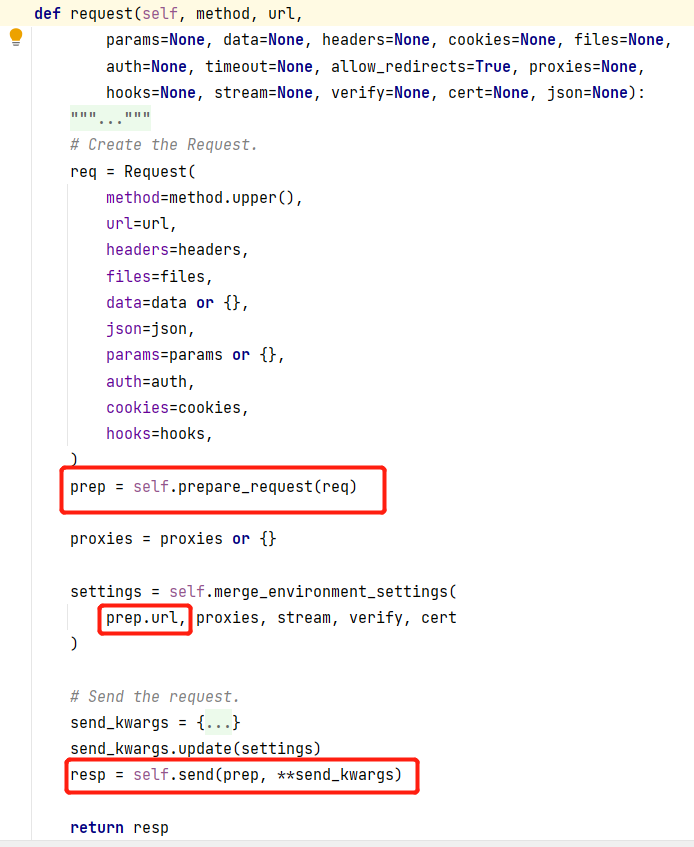
可以注意到主体最后使用了Session.send()发送请求,我们进入send()方法可以发现除了动态参数外,只有一个Request的实例,因此我们手动构造请求包其实也只需要构造一个Request的实例,相当于在url被规范化后,再重新给PreparedRequest的url赋值,达到发送“不规范”的url的效果
方案三 urllib3.HTTPConnectionPool
1 | pool = urllib3.HTTPConnectionPool("127.0.0.1", 8000) |
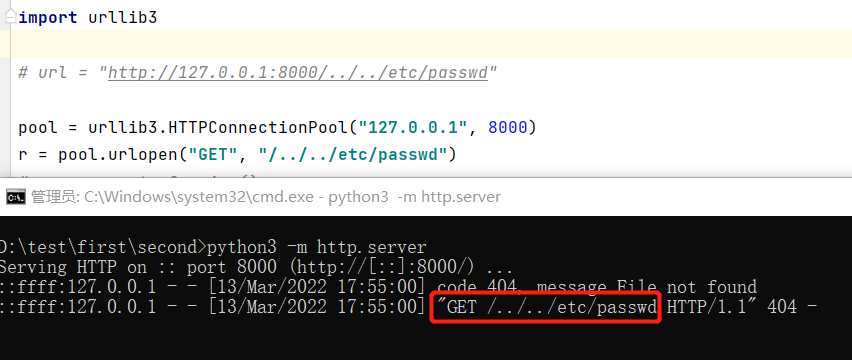
没问题,还是保存了点段
0x02 原理
从requests.Request的处理可以发现如下调用关系
1 | requests.api.get |
其中在send之前会调用prepare_request,而这正是url规范化的地方
requests.sessions.Session.prepare_request
=> requests.models.PreparedRequest.prepare
=> requests.models.PreparedRequest.prepare_url
=> urllib3.util.url._remove_path_dot_segments
在urllib3的一次commit中的src/urllib3/util/url.py第245行可以发现这处更新,注释也写到这里是为了遵循RFC3986的规范化
1 | def _remove_path_dot_segments(path): |
所以我们发送请求时需要避开这一步处理,方案一和方案三都是通过直接使用别的库来达成目的的,方案二则是在规范化后重新给url赋值,通过手动构造请求包的方式绕过规范化处理
0x03 一个坑点
需要注意的是,当send中含有proxies参数时,
1 | url = "https://example.com/../../../etc/passwd" |
会触发urllib3再次对url进行规范化处理
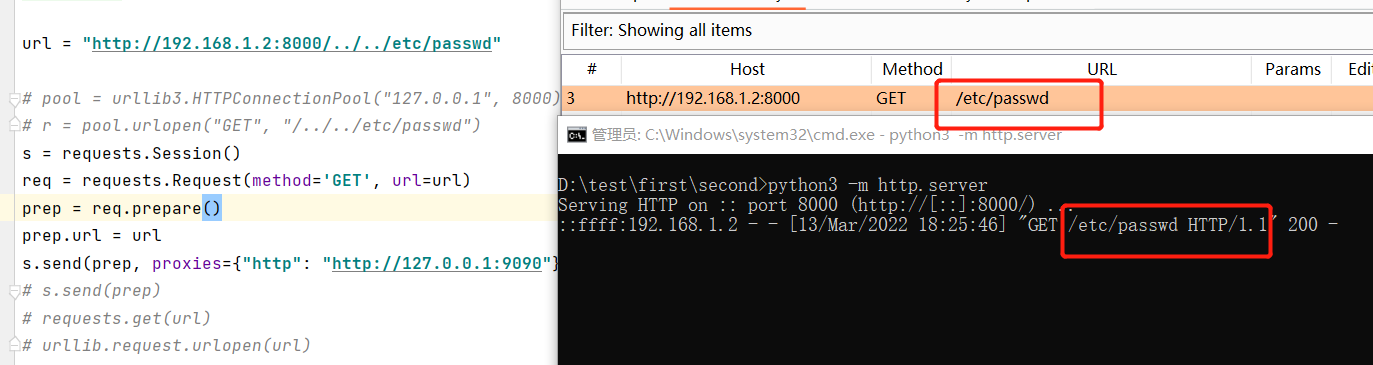
如上图所示,我们只是增加了一个代理的参数,就会导致url被重新处理
0x04 pocsuite3的处理
前面说到其实我是在用pocsuite3写poc时发现的这个问题,发现后我提了个issue,开发人员也很快的给了我解答并添加了hook,取消url的规范化,现在调用pocsuite3.api.requests便可以直接发送url了
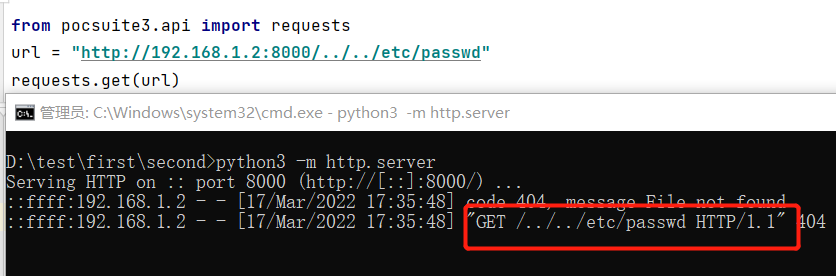
一个小插曲,在https://github.com/knownsec/pocsuite3/issues/268 ,一开始feat的是1.9.0版本,而这个版本还是没办法通过
request.get()直接发送url,要使用的话需要手动导入
2
3
4
5
from pocsuite3.lib.request.patch.hook_urllib3_parse_url import patch_urllib3_parse_url
patch_urllib3_parse_url()
url = "http://192.168.1.2:8000/../../etc/passwd"
requests.get(url)最后的1.9.1版本才可以直接使用
request.get()发送请求